Our products
" height="19.6944px" id="tMAW2sL8r" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(1.004 1)" width="33.99999375px"/><path d="M 16.945 0 L 16.945 17.958 L 0 27.805 L 0 9.847 Z" fill="rgb(227, 227, 240)" height="27.805370000000003px" id="JJvaBmqTN" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(18.055 10.652)" width="16.9455px"/><path d="M 17.055 9.847 L 17.058 27.805 L 0.004 17.958 L 0 0 Z" fill="rgb(255, 255, 255)" height="27.80527px" id="sJy5K17qe" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(1 10.652)" width="17.058135968px"/></svg>)
" height="10.12983px" id="apczVPUcG" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(9.525 10.764)" width="8.475220021787035px"/><path d="M 4.963 6.585 L 4.963 15.282 C 1.654 13.372 0 10.865 0 8.362 C 0 6.309 0.009 2.039 0.011 0 C 0.151 2.394 1.801 4.759 4.963 6.587 Z" fill="rgb(255, 255, 255)" height="15.2821px" id="QE19d8AIv" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(1.05 15.995)" width="4.96261px"/><path d="M 5.995 0 L 5.995 8.697 L 0 12.158 L 0 3.461 Z" fill="rgb(202, 204, 225)" height="12.158000000000001px" id="CSAfOGzI_" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(6.013 19.119)" width="5.995299999999999px"/><path d="M 8.477 4.893 L 8.477 11.769 C 8.477 10.517 7.65 9.262 5.993 8.306 C 4.341 7.352 2.172 6.876 0 6.873 L 0.003 0 C 2.174 0.003 4.341 0.48 5.993 1.433 C 7.65 2.389 8.477 3.641 8.477 4.893 Z" fill="rgb(227, 227, 240)" height="11.7687px" id="ewko0bm6r" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(18.003 12.588)" width="8.4773px"/><path d="M 8.475 0 L 8.475 6.876 L 0 6.876 L 0 0 Z" fill="rgb(202, 204, 225)" height="6.875599999999999px" id="GLJmg1tgS" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(26.48 17.481)" width="8.474800000000002px"/><path d="M 16.95 9.786 L 8.475 9.786 C 8.475 8.534 7.648 7.282 5.99 6.326 C 4.339 5.372 2.172 4.896 0 4.893 L 0 0 C 4.339 0 8.676 0.955 11.984 2.866 C 15.293 4.777 16.95 7.283 16.95 9.786 Z" fill="rgb(255, 255, 255)" height="9.786359999999998px" id="W9xZy2_qV" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(18.005 7.694)" width="16.949600000000004px"/><path d="M 0 9.786 L 0 14.921 C 4.411 14.955 8.843 13.998 12.209 12.055 C 13.847 11.109 15.078 10.019 15.907 8.855 C 16.749 7.665 17.174 6.401 17.177 5.135 L 17.177 0 C 17.18 0.632 8.488 6.401 8.064 6.997 C 7.648 7.577 7.035 8.121 6.215 8.595 C 4.505 9.582 2.244 9.82 0 9.788 Z" fill="rgb(255, 255, 255)" height="14.922149699097158px" id="lN4oiewJw" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(17.782 19.223)" width="17.176501180946563px"/><path d="M 0 4.891 L 0 9.786 C 4.411 9.82 8.843 8.863 12.209 6.92 C 13.846 5.974 15.078 4.884 15.907 3.72 C 16.749 2.53 17.174 1.266 17.176 0 L 8.698 0 C 8.702 0.632 8.488 1.267 8.066 1.862 C 7.649 2.442 7.037 2.986 6.216 3.46 C 4.506 4.447 2.245 4.924 0.001 4.892 Z" fill="rgb(255, 255, 255)" height="9.787244802421078px" id="fye1elKw2" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(17.782 19.223)" width="17.176399999999997px"/><path d="M 11.768 2.866 L 11.768 5.434 C 7.508 5.403 3.254 4.447 0 2.567 L 0 0 C 3.559 2.021 7.704 2.819 11.768 2.866 Z" fill="rgb(255, 255, 255)" height="5.433699999999998px" id="pP_zJLWBS" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(6.013 28.71)" width="11.767500000000002px"/><path d="M 11.768 1.432 L 11.768 6.328 C 7.704 6.282 3.56 5.481 0 3.461 L 5.997 0 C 7.596 0.924 9.674 1.4 11.768 1.431 Z" fill="rgb(255, 255, 255)" height="6.327500000000001px" id="E7Nspapf7" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(6.013 25.247)" width="11.767500000000002px"/><path d="M 16.942 0.002 L 16.942 2.082 L 16.94 4.894 C 14.77 4.894 12.601 5.372 10.946 6.328 C 7.638 8.238 7.637 11.34 10.946 13.25 L 4.951 16.71 C 1.789 14.884 0.14 12.518 0 10.124 C 0.002 9.728 0.002 9.476 0.002 9.419 L 0.002 9.408 C 0.16 7.032 1.809 4.681 4.953 2.865 C 8.262 0.955 12.603 -0.001 16.945 0 Z" fill="rgb(255, 255, 255)" height="16.710261204928212px" id="lYMcvBTvs" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.188406" stroke="rgb(26, 32, 117)" transform="translate(1.062 5.869)" width="16.944579999999995px"/><path d="M 17.286 0.259 L 17.426 0.052 C 17.405 0.038 17.382 0.027 17.358 0.019 Z M 17.305 0.282 L 17.536 0.187 L 17.536 0.187 Z M 17.306 0.314 L 17.064 0.251 C 17.058 0.272 17.056 0.293 17.056 0.314 Z M 17.306 2.075 L 17.056 2.075 C 17.056 2.213 17.167 2.325 17.305 2.325 Z M 29.265 4.948 L 29.392 4.733 L 29.39 4.732 Z M 29.571 5.13 L 29.701 4.916 L 29.699 4.915 Z M 34.255 11.91 L 34.005 11.91 C 34.005 11.917 34.005 11.923 34.006 11.929 Z M 34.257 13.641 L 34.007 13.641 C 34.007 13.665 34.01 13.689 34.017 13.713 Z M 34.26 13.655 L 34.51 13.655 L 34.51 13.654 Z M 34.26 18.79 L 34.51 18.795 L 34.51 18.79 Z M 34.255 19.03 L 34.505 19.041 L 34.505 19.035 Z M 33.135 22.314 L 33.342 22.455 L 33.344 22.452 Z M 32.981 22.54 L 33.185 22.685 L 33.188 22.681 Z M 29.57 25.575 L 29.698 25.79 L 29.7 25.789 Z M 29.267 25.755 L 29.392 25.971 L 29.394 25.97 Z M 17.86 28.623 L 17.862 28.873 L 17.865 28.873 Z M 17.032 28.628 L 16.855 28.805 C 16.903 28.852 16.967 28.878 17.034 28.878 Z M 17.031 28.627 L 17.208 28.45 C 17.137 28.379 17.029 28.357 16.936 28.396 C 16.842 28.435 16.781 28.526 16.781 28.627 Z M 17.031 28.628 L 17.029 28.878 C 17.096 28.878 17.16 28.852 17.207 28.805 C 17.255 28.758 17.281 28.695 17.281 28.628 Z M 5.238 25.755 L 5.363 25.538 L 5.363 25.538 Z M 0.25 18.79 L 0 18.79 L 0 18.79 Z M 0.261 10.44 L 0.511 10.441 L 0.511 10.44 Z M 0.261 10.425 L 0.011 10.424 L 0.011 10.425 Z M 0.264 9.722 L 0.514 9.723 L 0.514 9.722 Z M 0.264 9.707 L 0.015 9.685 C 0.014 9.693 0.014 9.7 0.014 9.707 Z M 0.283 9.481 L 0.035 9.455 L 0.034 9.46 Z M 5.239 3.122 L 5.117 2.904 L 5.114 2.906 Z M 5.554 2.945 L 5.433 2.726 L 5.431 2.727 Z M 17.257 0.25 L 17.329 0.011 C 17.305 0.004 17.281 0 17.257 0 Z M 17.248 13.944 L 17.272 13.696 C 17.264 13.695 17.256 13.694 17.248 13.694 Z M 11.311 15.356 L 11.186 15.139 C 11.109 15.183 11.061 15.266 11.061 15.356 Z M 11.311 19.648 L 11.061 19.648 C 11.061 19.738 11.109 19.821 11.186 19.865 Z M 16.98 21.058 L 16.976 21.308 C 17.043 21.309 17.108 21.283 17.156 21.236 C 17.204 21.189 17.23 21.125 17.23 21.058 Z M 16.98 18.546 L 16.742 18.472 C 16.734 18.496 16.73 18.521 16.73 18.546 Z M 16.989 18.518 L 16.781 18.38 C 16.768 18.399 16.758 18.421 16.751 18.444 Z M 17.013 18.498 L 16.918 18.267 L 16.917 18.267 Z M 17.044 18.496 L 16.987 18.74 C 17.004 18.744 17.022 18.746 17.041 18.746 Z M 23.223 17.07 L 23.348 17.287 L 23.352 17.284 Z M 23.519 16.892 L 23.648 17.106 L 23.653 17.102 Z M 24.397 16.223 L 24.565 16.407 C 24.617 16.36 24.646 16.293 24.647 16.223 C 24.647 16.153 24.617 16.086 24.565 16.038 Z M 23.52 15.553 L 23.654 15.342 L 23.649 15.339 Z M 23.22 15.371 L 23.349 15.157 L 23.345 15.155 Z M 17.659 13.951 L 17.666 13.701 L 17.663 13.701 Z M 17.253 13.945 L 17.257 13.695 L 17.253 13.695 Z M 17.286 0.259 L 17.146 0.466 C 17.109 0.441 17.086 0.407 17.074 0.378 L 17.305 0.282 L 17.536 0.187 C 17.516 0.138 17.48 0.088 17.426 0.052 Z M 17.305 0.282 L 17.073 0.377 C 17.05 0.32 17.058 0.272 17.064 0.251 L 17.306 0.314 L 17.548 0.378 C 17.558 0.336 17.568 0.265 17.536 0.187 Z M 17.306 0.314 L 17.056 0.314 L 17.056 2.075 L 17.306 2.075 L 17.556 2.075 L 17.556 0.314 Z M 17.306 2.075 L 17.305 2.325 C 21.602 2.333 25.881 3.282 29.14 5.165 L 29.265 4.948 L 29.39 4.732 C 26.037 2.795 21.667 1.833 17.306 1.825 Z M 29.265 4.948 L 29.137 5.163 L 29.444 5.345 L 29.571 5.13 L 29.699 4.915 L 29.392 4.733 Z M 29.571 5.13 L 29.442 5.344 C 32.51 7.207 34.004 9.579 34.005 11.91 L 34.255 11.91 L 34.505 11.91 C 34.503 9.346 32.86 6.835 29.701 4.916 Z M 34.255 11.91 L 34.006 11.929 C 34.008 11.957 34.014 11.98 34.021 11.997 C 34.027 12.015 34.034 12.028 34.039 12.037 C 34.044 12.046 34.049 12.053 34.052 12.056 C 34.053 12.058 34.054 12.06 34.055 12.06 C 34.055 12.061 34.056 12.062 34.055 12.061 C 34.055 12.061 34.055 12.06 34.054 12.059 C 34.053 12.058 34.052 12.056 34.05 12.054 C 34.047 12.05 34.042 12.042 34.036 12.032 C 34.031 12.021 34.024 12.006 34.018 11.987 C 34.012 11.967 34.007 11.943 34.007 11.914 L 34.257 11.914 L 34.507 11.914 C 34.507 11.885 34.502 11.86 34.496 11.84 C 34.49 11.821 34.482 11.805 34.477 11.795 C 34.471 11.784 34.466 11.776 34.462 11.771 C 34.459 11.767 34.457 11.763 34.457 11.763 C 34.456 11.762 34.458 11.764 34.46 11.767 C 34.462 11.77 34.466 11.777 34.471 11.785 C 34.476 11.794 34.483 11.807 34.49 11.824 C 34.496 11.841 34.502 11.864 34.504 11.891 Z M 34.257 11.914 L 34.007 11.914 L 34.007 13.641 L 34.257 13.641 L 34.507 13.641 L 34.507 11.914 Z M 34.257 13.641 L 34.017 13.713 C 34.019 13.717 34.017 13.711 34.015 13.703 C 34.013 13.694 34.01 13.678 34.01 13.657 L 34.26 13.655 L 34.51 13.654 C 34.51 13.628 34.506 13.606 34.503 13.592 C 34.501 13.585 34.499 13.58 34.498 13.576 C 34.497 13.572 34.496 13.569 34.496 13.569 Z M 34.26 13.655 L 34.01 13.655 L 34.01 18.79 L 34.26 18.79 L 34.51 18.79 L 34.51 13.655 Z M 34.26 18.79 L 34.01 18.785 L 34.005 19.025 L 34.255 19.03 L 34.505 19.035 L 34.51 18.795 Z M 34.255 19.03 L 34.005 19.019 C 33.958 20.086 33.599 21.154 32.926 22.177 L 33.135 22.314 L 33.344 22.452 C 34.061 21.363 34.454 20.209 34.505 19.041 Z M 33.135 22.314 L 32.928 22.174 L 32.775 22.4 L 32.981 22.54 L 33.188 22.681 L 33.342 22.455 Z M 32.981 22.54 L 32.778 22.395 C 32.019 23.46 30.91 24.469 29.441 25.362 L 29.57 25.575 L 29.7 25.789 C 31.216 24.869 32.379 23.816 33.185 22.685 Z M 29.57 25.575 L 29.443 25.36 L 29.139 25.54 L 29.267 25.755 L 29.394 25.97 L 29.698 25.79 Z M 29.267 25.755 L 29.142 25.538 C 26.022 27.339 21.964 28.289 17.855 28.373 L 17.86 28.623 L 17.865 28.873 C 22.037 28.788 26.182 27.824 29.392 25.971 Z M 17.86 28.623 L 17.859 28.373 L 17.031 28.378 L 17.032 28.628 L 17.034 28.878 L 17.862 28.873 Z M 17.032 28.628 L 17.209 28.451 L 17.208 28.45 L 17.031 28.627 L 16.854 28.804 L 16.855 28.805 Z M 17.031 28.627 L 16.781 28.627 L 16.781 28.628 L 17.031 28.628 L 17.281 28.628 L 17.281 28.627 Z M 17.031 28.628 L 17.033 28.378 C 12.799 28.347 8.581 27.396 5.363 25.538 L 5.238 25.755 L 5.113 25.971 C 8.423 27.883 12.732 28.847 17.029 28.878 Z M 5.238 25.755 L 5.363 25.538 C 2.091 23.649 0.5 21.197 0.5 18.79 L 0.25 18.79 L 0 18.79 C 0 21.438 1.75 24.029 5.113 25.971 Z M 0.25 18.79 L 0.5 18.79 C 0.5 16.742 0.508 12.485 0.511 10.441 L 0.261 10.44 L 0.011 10.44 C 0.008 12.484 0 16.741 0 18.79 Z M 0.261 10.44 L 0.511 10.44 L 0.511 10.425 L 0.261 10.425 L 0.011 10.425 L 0.011 10.44 Z M 0.261 10.425 L 0.511 10.426 L 0.514 9.723 L 0.264 9.722 L 0.014 9.721 L 0.011 10.424 Z M 0.264 9.722 L 0.514 9.722 L 0.514 9.707 L 0.264 9.707 L 0.014 9.707 L 0.014 9.722 Z M 0.264 9.707 L 0.513 9.729 L 0.532 9.503 L 0.283 9.481 L 0.034 9.46 L 0.015 9.685 Z M 0.283 9.481 L 0.532 9.508 C 0.766 7.292 2.352 5.079 5.364 3.339 L 5.239 3.122 L 5.114 2.906 C 2.018 4.694 0.291 7.027 0.035 9.455 Z M 5.239 3.122 L 5.362 3.34 L 5.676 3.163 L 5.554 2.945 L 5.431 2.727 L 5.117 2.904 Z M 5.554 2.945 L 5.674 3.164 C 8.905 1.391 13.076 0.499 17.257 0.5 L 17.257 0.25 L 17.257 0 C 13.013 -0.001 8.755 0.903 5.433 2.726 Z M 17.257 0.25 L 17.185 0.489 L 17.214 0.498 L 17.286 0.259 L 17.358 0.019 L 17.329 0.011 Z M 17.248 13.944 L 17.248 13.694 C 15.066 13.695 12.874 14.173 11.186 15.139 L 11.311 15.356 L 11.435 15.572 C 13.029 14.66 15.131 14.195 17.248 14.194 Z M 11.311 15.356 L 11.061 15.356 L 11.061 19.648 L 11.311 19.648 L 11.561 19.648 L 11.561 15.356 Z M 11.311 19.648 L 11.186 19.865 C 12.805 20.793 14.885 21.269 16.976 21.308 L 16.98 21.058 L 16.985 20.808 C 14.957 20.771 12.963 20.307 11.435 19.432 Z M 16.98 21.058 L 17.23 21.058 L 17.23 18.546 L 16.98 18.546 L 16.73 18.546 L 16.73 21.058 Z M 16.98 18.546 L 17.219 18.62 L 17.228 18.592 L 16.989 18.518 L 16.751 18.444 L 16.742 18.472 Z M 16.989 18.518 L 17.198 18.656 C 17.178 18.686 17.148 18.713 17.108 18.729 L 17.013 18.498 L 16.917 18.267 C 16.858 18.292 16.812 18.333 16.781 18.38 Z M 17.013 18.498 L 17.107 18.73 C 17.061 18.748 17.018 18.747 16.987 18.74 L 17.044 18.496 L 17.101 18.253 C 17.05 18.241 16.985 18.24 16.918 18.267 Z M 17.044 18.496 L 17.041 18.746 C 19.307 18.777 21.602 18.294 23.348 17.287 L 23.223 17.07 L 23.098 16.854 C 21.449 17.806 19.248 18.276 17.047 18.246 Z M 23.223 17.07 L 23.352 17.284 L 23.648 17.106 L 23.519 16.892 L 23.389 16.678 L 23.093 16.856 Z M 23.519 16.892 L 23.653 17.102 C 23.996 16.884 24.3 16.651 24.565 16.407 L 24.397 16.223 L 24.228 16.038 C 23.985 16.261 23.704 16.477 23.384 16.681 Z M 24.397 16.223 L 24.565 16.038 C 24.3 15.795 23.997 15.561 23.654 15.342 L 23.52 15.553 L 23.385 15.763 C 23.704 15.967 23.984 16.184 24.228 16.407 Z M 23.52 15.553 L 23.649 15.339 L 23.349 15.157 L 23.22 15.371 L 23.09 15.585 L 23.39 15.767 Z M 23.22 15.371 L 23.345 15.155 C 21.761 14.239 19.724 13.76 17.666 13.701 L 17.659 13.951 L 17.652 14.201 C 19.649 14.258 21.6 14.724 23.095 15.588 Z M 17.659 13.951 L 17.663 13.701 L 17.257 13.695 L 17.253 13.945 L 17.249 14.195 L 17.656 14.201 Z M 17.253 13.945 L 17.253 13.695 C 17.273 13.695 17.289 13.698 17.299 13.7 C 17.305 13.701 17.309 13.702 17.312 13.703 C 17.315 13.703 17.317 13.704 17.317 13.704 C 17.318 13.704 17.318 13.704 17.318 13.704 C 17.318 13.704 17.317 13.704 17.316 13.704 C 17.315 13.703 17.312 13.703 17.309 13.702 C 17.302 13.7 17.289 13.697 17.272 13.696 L 17.248 13.944 L 17.224 14.193 C 17.208 14.192 17.196 14.189 17.19 14.187 C 17.187 14.187 17.184 14.186 17.183 14.186 C 17.183 14.186 17.183 14.186 17.183 14.186 C 17.183 14.186 17.183 14.186 17.183 14.186 L 17.183 14.186 C 17.183 14.186 17.183 14.186 17.183 14.186 C 17.183 14.186 17.183 14.186 17.184 14.186 C 17.185 14.186 17.194 14.189 17.204 14.191 C 17.215 14.193 17.232 14.195 17.253 14.195 Z" fill="rgb(26, 32, 117)" height="28.87792911171687px" id="Ug6aKlzoq" transform="translate(1 5.5)" width="34.509724774169925px"/></svg>)
RESOURCES
" width="36px"><path d="M 0 36 L 0 0 L 36 0 L 36 36 Z" fill="transparent" height="36px" id="iUCdmHrYx" width="36px"/><path d="M 36 1.5 C 36 1.102 35.842 0.721 35.561 0.439 C 35.279 0.158 34.898 0 34.5 0 L 15.87 0 C 13.83 0 12.87 1.905 12.87 3.705 C 12.881 10.372 12.44 17.032 11.55 23.64 C 11.536 23.726 11.492 23.805 11.427 23.862 C 11.361 23.92 11.277 23.953 11.19 23.955 L 6.69 23.955 C 3.69 23.955 3.36 27.06 3.18 28.905 C 3 31.86 2.595 32.265 1.5 32.265 C 1.102 32.265 0.721 32.423 0.439 32.704 C 0.158 32.986 0 33.367 0 33.765 C 0 34.163 0.158 34.544 0.439 34.826 C 0.721 35.107 1.102 35.265 1.5 35.265 L 18.75 35.265 C 22.32 35.265 22.83 31.725 23.13 29.625 C 23.385 27.855 23.58 27.015 24 27.015 L 24.615 27.015 C 24.694 27.014 24.772 27.038 24.836 27.084 C 24.901 27.13 24.95 27.195 24.975 27.27 C 25.065 27.555 25.155 27.945 25.215 28.23 C 25.515 29.64 26.055 32.265 29.25 32.265 C 35.355 32.265 36 14.955 36 7.545 Z M 18.09 19.89 C 17.792 19.89 17.505 19.771 17.295 19.561 C 17.084 19.35 16.965 19.063 16.965 18.765 C 16.965 18.467 17.084 18.18 17.295 17.969 C 17.505 17.759 17.792 17.64 18.09 17.64 L 27.09 17.64 C 27.388 17.64 27.674 17.759 27.885 17.969 C 28.097 18.18 28.215 18.467 28.215 18.765 C 28.215 19.063 28.097 19.35 27.885 19.561 C 27.674 19.771 27.388 19.89 27.09 19.89 Z M 17.715 6.765 C 17.715 6.467 17.834 6.18 18.044 5.969 C 18.255 5.759 18.542 5.64 18.84 5.64 L 21.84 5.64 C 22.138 5.64 22.425 5.759 22.636 5.969 C 22.846 6.18 22.965 6.467 22.965 6.765 C 22.965 7.063 22.846 7.35 22.636 7.561 C 22.425 7.771 22.138 7.89 21.84 7.89 L 18.84 7.89 C 18.542 7.89 18.255 7.771 18.044 7.561 C 17.834 7.35 17.715 7.063 17.715 6.765 Z M 27.84 13.89 L 19.215 13.89 C 18.917 13.89 18.631 13.771 18.42 13.56 C 18.208 13.35 18.09 13.063 18.09 12.765 C 18.09 12.467 18.208 12.18 18.42 11.97 C 18.631 11.759 18.917 11.64 19.215 11.64 L 27.84 11.64 C 28.138 11.64 28.425 11.759 28.635 11.97 C 28.846 12.18 28.965 12.467 28.965 12.765 C 28.965 13.063 28.846 13.35 28.635 13.56 C 28.425 13.771 28.138 13.89 27.84 13.89 Z M 20.145 29.19 C 19.77 31.845 19.47 32.265 18.735 32.265 L 6.165 32.265 C 6.107 32.262 6.051 32.247 5.999 32.221 C 5.948 32.195 5.902 32.159 5.865 32.115 C 5.843 32.065 5.832 32.012 5.832 31.957 C 5.832 31.903 5.843 31.85 5.865 31.8 C 6.07 30.968 6.205 30.12 6.27 29.265 C 6.286 28.502 6.428 27.747 6.69 27.03 L 20.19 27.03 C 20.247 27.031 20.302 27.044 20.353 27.069 C 20.404 27.094 20.448 27.131 20.483 27.175 C 20.517 27.22 20.541 27.272 20.553 27.328 C 20.565 27.383 20.564 27.44 20.55 27.495 C 20.31 28.14 20.22 28.665 20.145 29.19 Z" fill="rgb(26, 32, 117)" height="35.2649682px" id="a9HQXIqwq" transform="translate(0 0.36)" width="36px"/></g></svg>)
" width="36px"><path d="M 0 36 L 0 0 L 36 0 L 36 36 Z" fill="transparent" height="36px" id="WHJWN5TkH" width="36px"/><path d="M 0 9.375 L 6.72 9.375 C 6.504 6.094 5.589 2.898 4.035 0 L 2.685 0 C 1.131 2.898 0.216 6.094 0 9.375 Z" fill="rgb(26, 32, 117)" height="9.374994000000001px" id="D4GeQFLRH" transform="translate(14.639 7.5)" width="6.71992200000002px"/><path d="M 4.905 8.805 C 5.079 5.762 5.812 2.778 7.065 0 C 5.171 0.642 3.5 1.812 2.249 3.372 C 0.997 4.932 0.217 6.817 0 8.805 Z" fill="rgb(26, 32, 117)" height="8.804988000000002px" id="jmtvry3iu" transform="translate(7.495 8.07)" width="7.065000000000022px"/><path d="M 2.1 8.805 L 7.005 8.805 C 6.793 6.824 6.022 4.944 4.782 3.385 C 3.541 1.826 1.883 0.652 0 0 C 1.233 2.782 1.945 5.766 2.1 8.805 Z" fill="rgb(26, 32, 117)" height="8.804988000000002px" id="IFfmxrmym" transform="translate(21.488 8.07)" width="7.005060000000025px"/><path d="M 2.16 0 C 1.986 3.043 1.254 6.027 0 8.805 C 1.894 8.162 3.565 6.993 4.817 5.433 C 6.068 3.873 6.848 1.988 7.065 0 Z" fill="rgb(26, 32, 117)" height="8.805060000000001px" id="NQ7dQhyno" transform="translate(21.431 19.125)" width="7.065000000000019px"/><path d="M 4.905 0 L 0 0 C 0.212 1.981 0.983 3.861 2.224 5.42 C 3.464 6.979 5.122 8.153 7.005 8.805 C 5.772 6.023 5.06 3.039 4.905 0 Z" fill="rgb(26, 32, 117)" height="8.805060000000001px" id="KE2e9uCl_" transform="translate(7.495 19.125)" width="7.005005999999958px"/><path d="M 6.72 0 L 0 0 C 0.223 3.28 1.138 6.475 2.685 9.375 L 4.035 9.375 C 5.589 6.477 6.504 3.281 6.72 0 Z" fill="rgb(26, 32, 117)" height="9.374939999999999px" id="DgtH1M3F6" transform="translate(14.639 19.125)" width="6.71992200000002px"/><path d="M 2.25 0 C 1.805 0 1.37 0.132 1 0.379 C 0.63 0.626 0.342 0.978 0.171 1.389 C 0.001 1.8 -0.044 2.253 0.043 2.689 C 0.13 3.125 0.344 3.526 0.659 3.841 C 0.974 4.156 1.375 4.37 1.811 4.457 C 2.247 4.544 2.7 4.499 3.111 4.329 C 3.522 4.158 3.874 3.87 4.121 3.5 C 4.368 3.13 4.5 2.695 4.5 2.25 C 4.5 1.653 4.263 1.081 3.841 0.659 C 3.419 0.237 2.847 0 2.25 0 Z" fill="rgb(26, 32, 117)" height="4.4999981102994px" id="yz2qIzO5V" transform="translate(15.75 0)" width="4.499998110299384px"/><path d="M 2.25 0 C 1.805 0 1.37 0.132 1 0.379 C 0.63 0.626 0.342 0.978 0.171 1.389 C 0.001 1.8 -0.044 2.253 0.043 2.689 C 0.13 3.125 0.344 3.526 0.659 3.841 C 0.974 4.156 1.375 4.37 1.811 4.457 C 2.247 4.544 2.7 4.499 3.111 4.329 C 3.522 4.158 3.874 3.87 4.121 3.5 C 4.368 3.13 4.5 2.695 4.5 2.25 C 4.5 1.653 4.263 1.081 3.841 0.659 C 3.419 0.237 2.847 0 2.25 0 Z" fill="rgb(26, 32, 117)" height="4.500013446863562px" id="J33nzg30y" transform="translate(15.75 31.5)" width="4.499998110299384px"/><path d="M 3.871 0.667 C 3.554 0.35 3.151 0.133 2.711 0.044 C 2.271 -0.044 1.815 0 1.401 0.171 C 0.986 0.342 0.632 0.633 0.382 1.005 C 0.133 1.378 0 1.817 0 2.265 C 0 2.713 0.133 3.152 0.382 3.525 C 0.632 3.897 0.986 4.188 1.401 4.359 C 1.815 4.53 2.271 4.574 2.711 4.486 C 3.151 4.397 3.554 4.18 3.871 3.862 C 4.289 3.436 4.524 2.863 4.524 2.265 C 4.524 1.667 4.289 1.094 3.871 0.667 Z" fill="rgb(26, 32, 117)" height="4.5299983854213535px" id="o3Jdq1LcG" transform="translate(26.859 4.598)" width="4.523940000000028px"/><path d="M 3.871 0.668 C 3.554 0.35 3.151 0.133 2.711 0.044 C 2.271 -0.044 1.815 0 1.401 0.171 C 0.986 0.342 0.632 0.633 0.383 1.005 C 0.133 1.378 0 1.817 0 2.265 C 0 2.714 0.133 3.152 0.383 3.525 C 0.632 3.897 0.986 4.188 1.401 4.359 C 1.815 4.53 2.271 4.574 2.711 4.486 C 3.151 4.397 3.554 4.18 3.871 3.863 C 4.289 3.436 4.524 2.863 4.524 2.265 C 4.524 1.667 4.289 1.094 3.871 0.668 Z" fill="rgb(26, 32, 117)" height="4.530084132375148px" id="XDC7YK0d4" transform="translate(4.598 26.872)" width="4.523904000000017px"/><path d="M 4.5 2.25 C 4.5 1.805 4.368 1.37 4.121 1 C 3.874 0.63 3.522 0.342 3.111 0.171 C 2.7 0.001 2.247 -0.044 1.811 0.043 C 1.375 0.13 0.974 0.344 0.659 0.659 C 0.344 0.974 0.13 1.375 0.043 1.811 C -0.044 2.247 0.001 2.7 0.171 3.111 C 0.342 3.522 0.63 3.874 1 4.121 C 1.37 4.368 1.805 4.5 2.25 4.5 C 2.847 4.5 3.419 4.263 3.841 3.841 C 4.263 3.419 4.5 2.847 4.5 2.25 Z" fill="rgb(26, 32, 117)" height="4.499998110299398px" id="asAn08OfD" transform="translate(31.5 15.75)" width="4.5000134468635675px"/><path d="M 4.5 2.25 C 4.5 1.805 4.368 1.37 4.121 1 C 3.874 0.63 3.522 0.342 3.111 0.171 C 2.7 0.001 2.247 -0.044 1.811 0.043 C 1.375 0.13 0.974 0.344 0.659 0.659 C 0.344 0.974 0.13 1.375 0.043 1.811 C -0.044 2.247 0.001 2.7 0.171 3.111 C 0.342 3.522 0.63 3.874 1 4.121 C 1.37 4.368 1.805 4.5 2.25 4.5 C 2.847 4.5 3.419 4.263 3.841 3.841 C 4.263 3.419 4.5 2.847 4.5 2.25 Z" fill="rgb(26, 32, 117)" height="4.499998110299398px" id="MCcs4r2LC" transform="translate(0 15.75)" width="4.5px"/><path d="M 3.862 3.871 C 4.18 3.554 4.397 3.151 4.486 2.711 C 4.574 2.271 4.53 1.815 4.359 1.401 C 4.188 0.986 3.897 0.632 3.525 0.383 C 3.152 0.133 2.714 0 2.265 0 C 1.817 0 1.378 0.133 1.005 0.383 C 0.633 0.632 0.342 0.986 0.171 1.401 C 0 1.815 -0.044 2.271 0.044 2.711 C 0.133 3.151 0.35 3.554 0.667 3.871 C 1.094 4.289 1.668 4.524 2.265 4.524 C 2.863 4.524 3.436 4.289 3.862 3.871 Z" fill="rgb(26, 32, 117)" height="4.52394px" id="Fy2le1HRj" transform="translate(26.873 26.864)" width="4.529997332022967px"/><path d="M 3.863 3.871 C 4.18 3.554 4.397 3.151 4.486 2.711 C 4.574 2.271 4.53 1.815 4.359 1.401 C 4.188 0.986 3.897 0.632 3.525 0.383 C 3.152 0.133 2.713 0 2.265 0 C 1.817 0 1.378 0.133 1.005 0.383 C 0.633 0.632 0.342 0.986 0.171 1.401 C 0 1.815 -0.044 2.271 0.044 2.711 C 0.133 3.151 0.35 3.554 0.668 3.871 C 1.094 4.289 1.667 4.524 2.265 4.524 C 2.863 4.524 3.436 4.289 3.863 3.871 Z" fill="rgb(26, 32, 117)" height="4.523904000000001px" id="oUwiWstd4" transform="translate(4.598 4.589)" width="4.530001661593019px"/></g></svg>)
" height="36px" id="scAYi6Xom" transform="translate(2.995 2)" width="29.9999532385908px"/></svg>)
Our products
RESOURCES
Introducing MakoraOptimize
Automated hyperparameter optimization for vLLM and SGLang

Introducing MakoraOptimize
Automated hyperparameter optimization for vLLM and SGLang
Introducing MakoraOptimize
Automated hyperparameter optimization for vLLM and SGLang
Introducing MakoraOptimize
Automated hyperparameter optimization for vLLM and SGLang
Real-world gains
MakoraOptimize delivers production-grade inference performance improvements.

88% lower time-to-first-token
on Llama-70B on Nvidia H100

Up to 61% higher throughput
on Llama-3.1-405B with 8× AMD MI300X

63% throughput boost
on Flux.1 Dev on a single AMD MI300X
Real-world gains
MakoraOptimize delivers production-grade inference performance improvements.
88% lower time-to-first-token
on Llama-70B on Nvidia H100
Up to 61% higher throughput
on Llama-3.1-405B with 8× AMD MI300X
63% throughput boost
on Flux.1 Dev on a single AMD MI300X
Real-world gains
MakoraOptimize delivers production-grade inference performance improvements.
88% lower time-to-first-token
on Llama-70B on Nvidia H100
Up to 61% higher throughput
on Llama-3.1-405B with 8× AMD MI300X
63% throughput boost
on Flux.1 Dev on a single AMD MI300X
Real-world gains
MakoraOptimize delivers production-grade inference performance improvements.
88% lower time-to-first-token
on Llama-70B on Nvidia H100
Up to 61% higher throughput
on Llama-3.1-405B with 8× AMD MI300X
63% throughput boost
on Flux.1 Dev on a single AMD MI300X
How it works
Makora's hyperparameter optimization engine makes sense of billions of inference engine configurations, automatically tuning for max performance.
1. Select model
2. Auto-tune vLLM/SGlang
3. Deploy anywhere
How it works
Makora's hyperparameter optimization engine makes sense of billions of inference engine configurations, automatically tuning for max performance.
1. Select model
2. Auto-tune vLLM/SGlang
3. Deploy anywhere
How it works
Makora's hyperparameter optimization engine makes sense of billions of inference engine configurations, automatically tuning for max performance.
1. Select model
2. Auto-tune vLLM/SGlang
3. Deploy anywhere
How it works
Makora's hyperparameter optimization engine makes sense of billions of inference engine configurations, automatically tuning for max performance.
1. Select model
2. Auto-tune vLLM/SGlang
3. Deploy anywhere
It’s as easy as one line of code
It’s as easy as one line of code
It’s as easy as one line of code
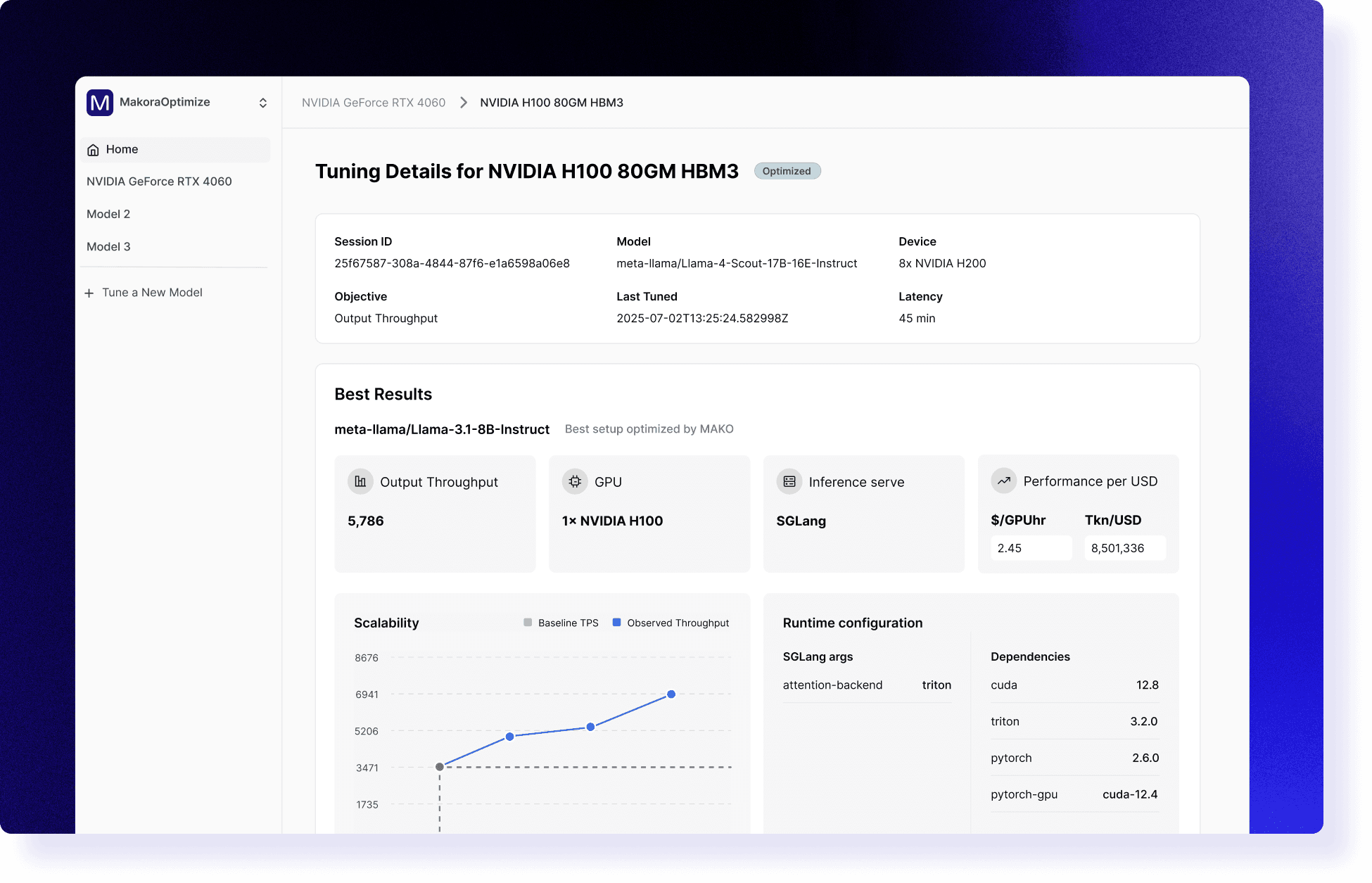
Monitor results in the MakoraOptimize dashboard
Monitor results in the
MakoOptimize dashboard
Monitor results in the MakoraOptimize dashboard
Core Features
Continuous, intelligent optimization
MakoraOptimize runs a 24/7 optimization loop across both the kernel and inference layers—constantly tuning for maximum throughput, lower latency, and better hardware utilization.
Hardware-agnostic and cloud-ready
Supports NVIDIA H100/H200, AMD MI300X, and major cloud platforms with zero vendor lock-in. No code rewrites or proprietary dependencies—run wherever your workloads live.
Built-in benchmarking performance insights
Monitor real-time performance with precision metrics. Understand latency, throughput, and hardware efficiency at every step—with data you can act on.
Seamless plug-and-play Integration
Drop into your existing stack without changing model architecture or inference engines. MakoraOptimize works with vLLM, SGLang, and more—right out of the box.
Core Features
Continuous, intelligent optimization
MakoraOptimize runs a 24/7 optimization loop across both the kernel and inference layers—constantly tuning for maximum throughput, lower latency, and better hardware utilization.
Hardware-agnostic and cloud-ready
Supports NVIDIA H100/H200, AMD MI300X, and major cloud platforms with zero vendor lock-in. No code rewrites or proprietary dependencies—run wherever your workloads live.
Built-in benchmarking performance insights
Monitor real-time performance with precision metrics. Understand latency, throughput, and hardware efficiency at every step—with data you can act on.
Seamless plug-and-play Integration
Drop into your existing stack without changing model architecture or inference engines. MakoraOptimize works with vLLM, SGLang, and more—right out of the box.
Core Features
Continuous, intelligent optimization
MakoraOptimize runs a 24/7 optimization loop across both the kernel and inference layers—constantly tuning for maximum throughput, lower latency, and better hardware utilization.
Hardware-agnostic and cloud-ready
Supports NVIDIA H100/H200, AMD MI300X, and major cloud platforms with zero vendor lock-in. No code rewrites or proprietary dependencies—run wherever your workloads live.
Built-in benchmarking performance insights
Monitor real-time performance with precision metrics. Understand latency, throughput, and hardware efficiency at every step—with data you can act on.
Seamless plug-and-play Integration
Drop into your existing stack without changing model architecture or inference engines. MakoraOptimize works with vLLM, SGLang, and more—right out of the box.
Core Features
Continuous, intelligent optimization
MakoraOptimize runs a 24/7 optimization loop across both the kernel and inference layers—constantly tuning for maximum throughput, lower latency, and better hardware utilization.
Hardware-agnostic and cloud-ready
Supports NVIDIA H100/H200, AMD MI300X, and major cloud platforms with zero vendor lock-in. No code rewrites or proprietary dependencies—run wherever your workloads live.
Built-in benchmarking performance insights
Monitor real-time performance with precision metrics. Understand latency, throughput, and hardware efficiency at every step—with data you can act on.
Seamless plug-and-play Integration
Drop into your existing stack without changing model architecture or inference engines. MakoraOptimize works with vLLM, SGLang, and more—right out of the box.
What our customers say


“Makora’s GPU kernel optimization capabilities and Microsoft Azure’s AI infrastructure makes it easier to scale AI workloads.”
“Makora’s GPU kernel optimization capabilities and Microsoft Azure’s AI infrastructure makes it easier to scale AI workloads.”
Tom Davis
Partner, Microsoft for Startups Program

What kinds of applications benefit from Makora?
Large language models, transformer architectures, and high-throughput inference workloads see significant performance gains. Computer vision models, recommendation systems, and any GPU-bottlenecked application also benefit from automated kernel optimization.
Do I need to know CUDA to use Makora?
Not at all. MakoraOptimize handles all GPU programming complexity automatically. You can describe logic in Python-like syntax or natural language, and Makora handles the rest.
Can Makora be used in production today?
Yes. We're working with early adopters in production environments now. Join the waitlist to get early access and hands-on support.
What kinds of applications benefit from Makora?
Large language models, transformer architectures, and high-throughput inference workloads see significant performance gains. Computer vision models, recommendation systems, and any GPU-bottlenecked application also benefit from automated kernel optimization.
Do I need to know CUDA to use Makora?
Not at all. MakoraOptimize handles all GPU programming complexity automatically. You can describe logic in Python-like syntax or natural language, and Makora handles the rest.
Can Makora be used in production today?
Yes. We're working with early adopters in production environments now. Join the waitlist to get early access and hands-on support.
What kinds of applications benefit from Makora?
Large language models, transformer architectures, and high-throughput inference workloads see significant performance gains. Computer vision models, recommendation systems, and any GPU-bottlenecked application also benefit from automated kernel optimization.
Do I need to know CUDA to use Makora?
Not at all. MakoraOptimize handles all GPU programming complexity automatically. You can describe logic in Python-like syntax or natural language, and Makora handles the rest.
Can Makora be used in production today?
Yes. We're working with early adopters in production environments now. Join the waitlist to get early access and hands-on support.
What kinds of applications benefit from Makora?
Large language models, transformer architectures, and high-throughput inference workloads see significant performance gains. Computer vision models, recommendation systems, and any GPU-bottlenecked application also benefit from automated kernel optimization.
Do I need to know CUDA to use Makora?
Not at all. MakoraOptimize handles all GPU programming complexity automatically. You can describe logic in Python-like syntax or natural language, and Makora handles the rest.
Can Makora be used in production today?
Yes. We're working with early adopters in production environments now. Join the waitlist to get early access and hands-on support.

Products
company

Copyright © 2025 MakoRA. All rights reserved.
Products
company
Copyright © 2025 MakoRA. All rights reserved.
Products
company
Copyright © 2025 MakoRA. All rights reserved.
Products
company
Copyright © 2025 MakoRA. All rights reserved.