" height="19.6944px" id="tMAW2sL8r" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(1.004 1)" width="33.99999375px"/><path d="M 16.945 0 L 16.945 17.958 L 0 27.805 L 0 9.847 Z" fill="rgb(227, 227, 240)" height="27.805370000000003px" id="JJvaBmqTN" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(18.055 10.652)" width="16.9455px"/><path d="M 17.055 9.847 L 17.058 27.805 L 0.004 17.958 L 0 0 Z" fill="rgb(255, 255, 255)" height="27.80527px" id="sJy5K17qe" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(1 10.652)" width="17.058135968px"/></svg>)
" width="36px"><path d="M 0 36 L 0 0 L 36 0 L 36 36 Z" fill="transparent" height="36px" id="WHJWN5TkH" width="36px"/><path d="M 0 9.375 L 6.72 9.375 C 6.504 6.094 5.589 2.898 4.035 0 L 2.685 0 C 1.131 2.898 0.216 6.094 0 9.375 Z" fill="rgb(26, 32, 117)" height="9.374994000000001px" id="D4GeQFLRH" transform="translate(14.639 7.5)" width="6.71992200000002px"/><path d="M 4.905 8.805 C 5.079 5.762 5.812 2.778 7.065 0 C 5.171 0.642 3.5 1.812 2.249 3.372 C 0.997 4.932 0.217 6.817 0 8.805 Z" fill="rgb(26, 32, 117)" height="8.804988000000002px" id="jmtvry3iu" transform="translate(7.495 8.07)" width="7.065000000000022px"/><path d="M 2.1 8.805 L 7.005 8.805 C 6.793 6.824 6.022 4.944 4.782 3.385 C 3.541 1.826 1.883 0.652 0 0 C 1.233 2.782 1.945 5.766 2.1 8.805 Z" fill="rgb(26, 32, 117)" height="8.804988000000002px" id="IFfmxrmym" transform="translate(21.488 8.07)" width="7.005060000000025px"/><path d="M 2.16 0 C 1.986 3.043 1.254 6.027 0 8.805 C 1.894 8.162 3.565 6.993 4.817 5.433 C 6.068 3.873 6.848 1.988 7.065 0 Z" fill="rgb(26, 32, 117)" height="8.805060000000001px" id="NQ7dQhyno" transform="translate(21.431 19.125)" width="7.065000000000019px"/><path d="M 4.905 0 L 0 0 C 0.212 1.981 0.983 3.861 2.224 5.42 C 3.464 6.979 5.122 8.153 7.005 8.805 C 5.772 6.023 5.06 3.039 4.905 0 Z" fill="rgb(26, 32, 117)" height="8.805060000000001px" id="KE2e9uCl_" transform="translate(7.495 19.125)" width="7.005005999999958px"/><path d="M 6.72 0 L 0 0 C 0.223 3.28 1.138 6.475 2.685 9.375 L 4.035 9.375 C 5.589 6.477 6.504 3.281 6.72 0 Z" fill="rgb(26, 32, 117)" height="9.374939999999999px" id="DgtH1M3F6" transform="translate(14.639 19.125)" width="6.71992200000002px"/><path d="M 2.25 0 C 1.805 0 1.37 0.132 1 0.379 C 0.63 0.626 0.342 0.978 0.171 1.389 C 0.001 1.8 -0.044 2.253 0.043 2.689 C 0.13 3.125 0.344 3.526 0.659 3.841 C 0.974 4.156 1.375 4.37 1.811 4.457 C 2.247 4.544 2.7 4.499 3.111 4.329 C 3.522 4.158 3.874 3.87 4.121 3.5 C 4.368 3.13 4.5 2.695 4.5 2.25 C 4.5 1.653 4.263 1.081 3.841 0.659 C 3.419 0.237 2.847 0 2.25 0 Z" fill="rgb(26, 32, 117)" height="4.4999981102994px" id="yz2qIzO5V" transform="translate(15.75 0)" width="4.499998110299384px"/><path d="M 2.25 0 C 1.805 0 1.37 0.132 1 0.379 C 0.63 0.626 0.342 0.978 0.171 1.389 C 0.001 1.8 -0.044 2.253 0.043 2.689 C 0.13 3.125 0.344 3.526 0.659 3.841 C 0.974 4.156 1.375 4.37 1.811 4.457 C 2.247 4.544 2.7 4.499 3.111 4.329 C 3.522 4.158 3.874 3.87 4.121 3.5 C 4.368 3.13 4.5 2.695 4.5 2.25 C 4.5 1.653 4.263 1.081 3.841 0.659 C 3.419 0.237 2.847 0 2.25 0 Z" fill="rgb(26, 32, 117)" height="4.500013446863562px" id="J33nzg30y" transform="translate(15.75 31.5)" width="4.499998110299384px"/><path d="M 3.871 0.667 C 3.554 0.35 3.151 0.133 2.711 0.044 C 2.271 -0.044 1.815 0 1.401 0.171 C 0.986 0.342 0.632 0.633 0.382 1.005 C 0.133 1.378 0 1.817 0 2.265 C 0 2.713 0.133 3.152 0.382 3.525 C 0.632 3.897 0.986 4.188 1.401 4.359 C 1.815 4.53 2.271 4.574 2.711 4.486 C 3.151 4.397 3.554 4.18 3.871 3.862 C 4.289 3.436 4.524 2.863 4.524 2.265 C 4.524 1.667 4.289 1.094 3.871 0.667 Z" fill="rgb(26, 32, 117)" height="4.5299983854213535px" id="o3Jdq1LcG" transform="translate(26.859 4.598)" width="4.523940000000028px"/><path d="M 3.871 0.668 C 3.554 0.35 3.151 0.133 2.711 0.044 C 2.271 -0.044 1.815 0 1.401 0.171 C 0.986 0.342 0.632 0.633 0.383 1.005 C 0.133 1.378 0 1.817 0 2.265 C 0 2.714 0.133 3.152 0.383 3.525 C 0.632 3.897 0.986 4.188 1.401 4.359 C 1.815 4.53 2.271 4.574 2.711 4.486 C 3.151 4.397 3.554 4.18 3.871 3.863 C 4.289 3.436 4.524 2.863 4.524 2.265 C 4.524 1.667 4.289 1.094 3.871 0.668 Z" fill="rgb(26, 32, 117)" height="4.530084132375148px" id="XDC7YK0d4" transform="translate(4.598 26.872)" width="4.523904000000017px"/><path d="M 4.5 2.25 C 4.5 1.805 4.368 1.37 4.121 1 C 3.874 0.63 3.522 0.342 3.111 0.171 C 2.7 0.001 2.247 -0.044 1.811 0.043 C 1.375 0.13 0.974 0.344 0.659 0.659 C 0.344 0.974 0.13 1.375 0.043 1.811 C -0.044 2.247 0.001 2.7 0.171 3.111 C 0.342 3.522 0.63 3.874 1 4.121 C 1.37 4.368 1.805 4.5 2.25 4.5 C 2.847 4.5 3.419 4.263 3.841 3.841 C 4.263 3.419 4.5 2.847 4.5 2.25 Z" fill="rgb(26, 32, 117)" height="4.499998110299398px" id="asAn08OfD" transform="translate(31.5 15.75)" width="4.5000134468635675px"/><path d="M 4.5 2.25 C 4.5 1.805 4.368 1.37 4.121 1 C 3.874 0.63 3.522 0.342 3.111 0.171 C 2.7 0.001 2.247 -0.044 1.811 0.043 C 1.375 0.13 0.974 0.344 0.659 0.659 C 0.344 0.974 0.13 1.375 0.043 1.811 C -0.044 2.247 0.001 2.7 0.171 3.111 C 0.342 3.522 0.63 3.874 1 4.121 C 1.37 4.368 1.805 4.5 2.25 4.5 C 2.847 4.5 3.419 4.263 3.841 3.841 C 4.263 3.419 4.5 2.847 4.5 2.25 Z" fill="rgb(26, 32, 117)" height="4.499998110299398px" id="MCcs4r2LC" transform="translate(0 15.75)" width="4.5px"/><path d="M 3.862 3.871 C 4.18 3.554 4.397 3.151 4.486 2.711 C 4.574 2.271 4.53 1.815 4.359 1.401 C 4.188 0.986 3.897 0.632 3.525 0.383 C 3.152 0.133 2.714 0 2.265 0 C 1.817 0 1.378 0.133 1.005 0.383 C 0.633 0.632 0.342 0.986 0.171 1.401 C 0 1.815 -0.044 2.271 0.044 2.711 C 0.133 3.151 0.35 3.554 0.667 3.871 C 1.094 4.289 1.668 4.524 2.265 4.524 C 2.863 4.524 3.436 4.289 3.862 3.871 Z" fill="rgb(26, 32, 117)" height="4.52394px" id="Fy2le1HRj" transform="translate(26.873 26.864)" width="4.529997332022967px"/><path d="M 3.863 3.871 C 4.18 3.554 4.397 3.151 4.486 2.711 C 4.574 2.271 4.53 1.815 4.359 1.401 C 4.188 0.986 3.897 0.632 3.525 0.383 C 3.152 0.133 2.713 0 2.265 0 C 1.817 0 1.378 0.133 1.005 0.383 C 0.633 0.632 0.342 0.986 0.171 1.401 C 0 1.815 -0.044 2.271 0.044 2.711 C 0.133 3.151 0.35 3.554 0.668 3.871 C 1.094 4.289 1.667 4.524 2.265 4.524 C 2.863 4.524 3.436 4.289 3.863 3.871 Z" fill="rgb(26, 32, 117)" height="4.523904000000001px" id="oUwiWstd4" transform="translate(4.598 4.589)" width="4.530001661593019px"/></g></svg>)
" height="36px" id="scAYi6Xom" transform="translate(2.995 2)" width="29.9999532385908px"/></svg>)

Written by
Published on
TLDR; MakoraGenerate implements Kimi Delta Attention kernels that outperform PyTorch by 5-7x and match expert-written kernel latency on some shapes. The kernels are available for inspection here.
The attention mechanism is among the most important building blocks of deep neural networks. Despite the original implementation’s success, its quadratic compute cost and linear memory footprint have motivated a wave of more efficient variants. The research community has responded with increasingly sophisticated designs, such as Kimi Delta Attention (KDA) from the Kimi-K2 model [1], that offer substantial theoretical and empirical advantages. However, these variants often lie outside the optimization envelope of PyTorch and even torch.compile, requiring bespoke, hand-tuned GPU kernels that only a small number of experts can produce. This dependency on specialized kernel engineering has become a key bottleneck, limiting how many attention variants can be implemented, evaluated, and scaled in practice.
This blog post shows how MakoraGenerate (formerly MakoGenerate), our LLM coding agent for writing GPU kernels, overcomes this bottleneck. By exploring KDA, the core mechanism behind Moonshot AI’s Kimi Linear architecture [2], we dissect why standard compilers struggle, how expert Triton kernels overcome those limitations, and how MakoraGenerate automatically produces kernels that match expert-level performance in minutes, rather than the days or weeks required by manual engineering. This introduces a new paradigm that allows us to explore new attention variants at a rate that was never before possible.
The Kimi Delta Attention (KDA) Algorithm
To understand the optimization challenge, we first need to understand the math. Unlike standard attention, which computes an O(T²) similarity matrix, KDA maintains a fixed-size state:

Which compresses history, making it a linear attention mechanism that formulates context processing as a Recurrent Neural Network (RNN). It refines the delta rule, which updates the state based on the error between actual and predicted values, by adding fine-grained, channel-wise gating. The recurrent update rule proceeds in three steps:
Step 1 — Decay (forget old information):

Step 2 — Predict & Correct (delta rule):
We first estimate the value using the decayed state, then compute the error to update the state.
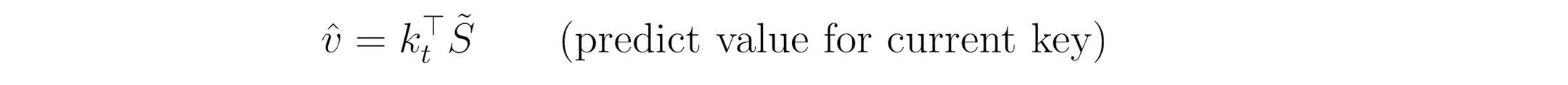
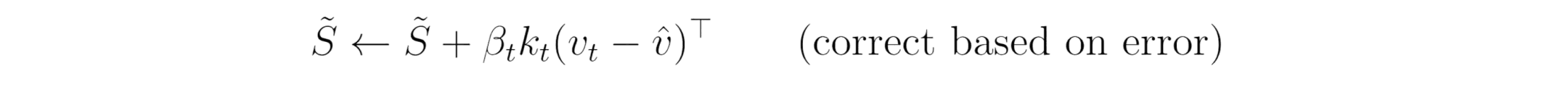
Note: This assignment defines the new state used for the next time step.
Step 3 — Output (read from memory):

Where:

This predict-then-correct mechanism is what gives KDA its name. It applies the delta rule from neural network learning, treating the state matrix as an associative memory that continuously refines itself.
The Hardware Challenge
Mathematically, this is elegant. Computationally, it is a memory transfer nightmare.
For inference, we use KDA's recurrent formulation rather than the chunked parallel version designed for training. In this mode, the state matrix S must be read, updated, and written back at every single token. This state is large: for typical head dimensions, S contains hundreds of thousands to millions of elements. In our test cases with K=256 and V=8192, that's 4MB of data per head.
A naive implementation treats each time step independently: read the entire state S from GPU global memory (HBM), perform a handful of arithmetic operations, then write the entire state back. The problem is that GPUs are designed for compute-heavy workloads, not repeatedly moving data back and forth. Modern accelerators like NVIDIA H100 can perform orders of magnitude more arithmetic operations than they can transfer bytes at the same time. With arithmetic intensity this low, the kernel spends most of its time moving data rather than computing, leaving the vast majority of the GPU's compute capability idle.
This is a classic memory-bound bottleneck. The state S makes a round-trip to HBM for every token in the sequence, and no amount of raw FLOPS can compensate for that bandwidth wall.
TorchInductor: Good, but not Enough
We ran a naive PyTorch implementation of KDA through torch.compile (using the default Inductor backend). While functional, it struggled to overcome the memory wall.
The compiler often fails to identify that is a transient accumulator that should live in the GPU's registers or Shared Memory (SRAM). Instead, it materializes the state to HBM at every step to ensure safety for the autograd graph. This results in the implementation running at a fraction of the hardware's peak throughput.
The Hand-Optimized Triton Solution
Expert kernel engineers solve this problem by allocating S in fast on-chip SRAM and keeping it there for the entire sequence, instead of reading and writing S from HBM every token.
The optimized Triton kernel declares the state as a Triton tensor, ensuring that it resides in registers or shared memory rather than global memory:
This restructuring significantly reduces memory traffic. The naive approach reads and writes S (8MB round-trip) for every token, totaling 8MB × T for a sequence of length T. The optimized kernel only reads inputs (q, k, v, g, beta) and writes outputs, roughly 50KB × T. That's approximately 160× less memory traffic for the same computation, pushing arithmetic intensity from 0.06 to nearly 10 FLOP/byte.
Beyond the fundamental SRAM insight, the kernel applies several additional optimizations. It parallelizes across batch, head, and V dimensions by launching a grid of (B × H, ceil(V / BLOCK_V)) thread blocks. Each block processes a BLOCK_K × BLOCK_V tile of the state matrix, sized to fit comfortably in registers. All four operations (decay, predict, write, read) are fused within a single loop iteration, eliminating intermediate stores. The kernel also uses FP32 accumulation for numerical stability, converting back to the original data type only when storing final outputs.
Generating an Expert-Quality Kernel Automatically
We tasked MakoraGenerate with optimizing KDA. We provide the Kimi Linear Attention paper and the reference PyTorch implementation as inputs, then compare the results to the hand-optimized kernels from the Flash Linear Attention (FLA) repository [3], as well as the performance of torch.compile in default mode. The full kernel generation run takes about 5 minutes to materialize a baseline, then iterates using evolutionary search to improve the kernel for an additional hour.
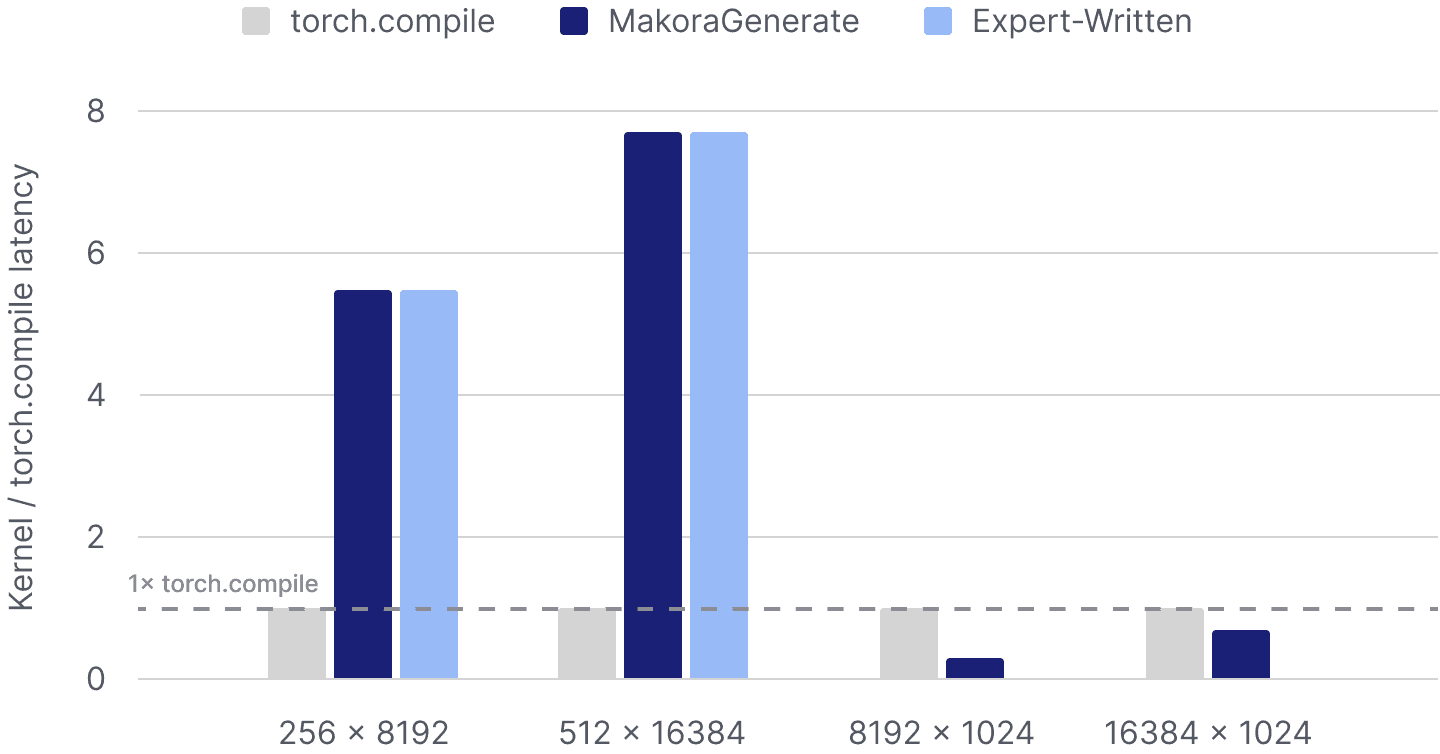
When a PyTorch reference problem is passed to MakoraGenerate, a user specifies input shapes to test against. In this example, we develop separate Triton kernels for each input shape, and for the NVIDIA H100 GPU. We choose four shapes that are relevant for low-to-medium context length use cases. Results are shown below.
Input x Output token lengths (K x V) | Use Case | Torch. | MakoraGenerate | Expert-Written |
|---|---|---|---|---|
256 x 8192 | Small reasoning | 1x | 5.8x | 5.8x |
512 x 16384 | Medium reasoning | 1x | 7.9x | 7.8x |
8192 x 1024 | Small RAG | 1x | 0.34x | ❌ Runtime Error |
16384 x 1024 | Medium RAG | 1x | 0.71x | ❌ Runtime Error |
We benchmarked performance using standard best-practice methodology (discard warmups, cache clearing, etc.), and the results show evidence that the agent can automatically generate kernels that match expert-level performance while substantially outperforming compiler-generated baselines. At K=256, V=8192, the agent delivered a 5.6x speedup over torch.compile matching the hand-tuned implementation; at K=512, V=16384, it achieved an even larger 7.8x speedup, again reaching parity with the expert kernel. These results demonstrate that the agent can reliably close the performance gap traditionally reserved for specialized human-engineered kernels.
Performance does decline on the largest shapes we tested: at K=8192, V=1024, throughput drops to 0.34× of the baseline, and at K=16384, V=1024 it reaches 0.71×. These shapes expose a clear frontier for further optimization, where larger K-dimensions make tiling, memory traffic, and register pressure more challenging.
However, what’s particularly noteworthy is that on these same large shapes, the hand-optimized FLA baseline fails entirely, hanging during kernel compilation with nvcc as its heuristics break down outside typical parameter regimes. The agent-generated kernels, by contrast, compile and run successfully, handling cases that human-designed heuristics cannot, even if performance remains below the expert baseline where it does succeed. This robustness underscores the agent’s ability not just to match human experts on favorable shapes, but to generalize beyond the reliability envelope of existing hand-tuned kernels.
Kernel Performance vs torch.compile
What the Agent Did Right
Examining the generated code reveals that the agent correctly identified memory bandwidth as the core bottleneck and applied the critical optimization of keeping state in SRAM across the time loop. The kernel structure mirrors expert implementations, with pre-computed base pointers outside the loop, proper tiling with BLOCK_K = next_power_of_2(K) and BLOCK_V = 128 , and carefully The agent also made subtle but important decisions around numerical stability. All computations happen in FP32 with explicit .to(tl.float32) conversions on load, and the scaling factor is applied directly to queries rather than being folded into a later operation. Boundary conditions are handled correctly with masks, preventing out-of-bounds memory access that could cause silent correctness issues.
Comparing the agent's output to the FLA baseline reveals an interesting tradeoff. The FLA implementation is more general-purpose, supporting multiple gating modes (scalar g, per-key gk, per-value gv), variable-length sequences, and optional initial/final state handling through extensive use of @triton.heuristics for conditional compilation. This flexibility comes at the cost of complexity, as more code paths mean more opportunities for edge cases to break. The agent's kernel is more specialized to the exact KDA formulation, resulting in cleaner code that proves more robust on a variety of input shapes.
The entire optimization process took a few hours of agent compute time, compared to the days or weeks of manual tuning that experts usually contribute to kernel generation. This represents a fundamental shift in how performance-critical kernels can be developed: describe the algorithm, provide reference implementations, and let the agent explore the optimization space.
Limitations and Next Steps
In many cases, generated kernels generalize across shapes. In this case, the generated kernels do not. Therefore, we generate separate Triton kernels for each input shape. A next step would be to pass both of these kernels to MakoraGenerate, and ask it to produce a kernel that maintains performance across both shapes. The agent could deploy conditional logic, or perhaps discover an implementation that works across a wider variety of input shapes.
Another issue is the failing compile of the FLA kernel on the larger shapes. This could be an issue that we just didn’t put enough effort into debugging. If someone gets it working, let us know and we’ll update this blog post.
Conclusion
KDA exposes the limits of general-purpose compilers like torch.compile, which cannot recognize that a recurrent state should live in fast on-chip memory rather than making round-trips to HBM every token. The fix required domain-specific restructuring: keep the state in SRAM across the sequential loop.
MakoraGenerate, the industry-leading GPU kernel coding agent, independently identified this expert insight automatically, achieving 5.6 to 7.8x speedup over Inductor and matching hand-optimized baselines in minutes rather than weeks of manual tuning. As new attention algorithms and new hardware accelerators continue to evolve, this kind of automated kernel optimization shifts becomes essential to keep up with progress in the field.
[1] Kimi K2: Open Agentic Intelligence (Kimi et. al., 2025), https://www.arxiv.org/abs/2507.20534
[2] Kimi Linear: An Expressive, Efficient Attention Architecture (Kimi Team et. al., 2025) https://arxiv.org/abs/2510.26692
[3] Flash Linear Attention Github Repo, https://github.com/fla-org/flash-linear-attention/tree/main/fla/ops/kda
Latest
From the blog
The latest industry news, interviews, technologies, and resources.



