" height="19.6944px" id="tMAW2sL8r" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(1.004 1)" width="33.99999375px"/><path d="M 16.945 0 L 16.945 17.958 L 0 27.805 L 0 9.847 Z" fill="rgb(227, 227, 240)" height="27.805370000000003px" id="JJvaBmqTN" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(18.055 10.652)" width="16.9455px"/><path d="M 17.055 9.847 L 17.058 27.805 L 0.004 17.958 L 0 0 Z" fill="rgb(255, 255, 255)" height="27.80527px" id="sJy5K17qe" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(1 10.652)" width="17.058135968px"/></svg>)
" width="36px"><path d="M 0 36 L 0 0 L 36 0 L 36 36 Z" fill="transparent" height="36px" id="WHJWN5TkH" width="36px"/><path d="M 0 9.375 L 6.72 9.375 C 6.504 6.094 5.589 2.898 4.035 0 L 2.685 0 C 1.131 2.898 0.216 6.094 0 9.375 Z" fill="rgb(26, 32, 117)" height="9.374994000000001px" id="D4GeQFLRH" transform="translate(14.639 7.5)" width="6.71992200000002px"/><path d="M 4.905 8.805 C 5.079 5.762 5.812 2.778 7.065 0 C 5.171 0.642 3.5 1.812 2.249 3.372 C 0.997 4.932 0.217 6.817 0 8.805 Z" fill="rgb(26, 32, 117)" height="8.804988000000002px" id="jmtvry3iu" transform="translate(7.495 8.07)" width="7.065000000000022px"/><path d="M 2.1 8.805 L 7.005 8.805 C 6.793 6.824 6.022 4.944 4.782 3.385 C 3.541 1.826 1.883 0.652 0 0 C 1.233 2.782 1.945 5.766 2.1 8.805 Z" fill="rgb(26, 32, 117)" height="8.804988000000002px" id="IFfmxrmym" transform="translate(21.488 8.07)" width="7.005060000000025px"/><path d="M 2.16 0 C 1.986 3.043 1.254 6.027 0 8.805 C 1.894 8.162 3.565 6.993 4.817 5.433 C 6.068 3.873 6.848 1.988 7.065 0 Z" fill="rgb(26, 32, 117)" height="8.805060000000001px" id="NQ7dQhyno" transform="translate(21.431 19.125)" width="7.065000000000019px"/><path d="M 4.905 0 L 0 0 C 0.212 1.981 0.983 3.861 2.224 5.42 C 3.464 6.979 5.122 8.153 7.005 8.805 C 5.772 6.023 5.06 3.039 4.905 0 Z" fill="rgb(26, 32, 117)" height="8.805060000000001px" id="KE2e9uCl_" transform="translate(7.495 19.125)" width="7.005005999999958px"/><path d="M 6.72 0 L 0 0 C 0.223 3.28 1.138 6.475 2.685 9.375 L 4.035 9.375 C 5.589 6.477 6.504 3.281 6.72 0 Z" fill="rgb(26, 32, 117)" height="9.374939999999999px" id="DgtH1M3F6" transform="translate(14.639 19.125)" width="6.71992200000002px"/><path d="M 2.25 0 C 1.805 0 1.37 0.132 1 0.379 C 0.63 0.626 0.342 0.978 0.171 1.389 C 0.001 1.8 -0.044 2.253 0.043 2.689 C 0.13 3.125 0.344 3.526 0.659 3.841 C 0.974 4.156 1.375 4.37 1.811 4.457 C 2.247 4.544 2.7 4.499 3.111 4.329 C 3.522 4.158 3.874 3.87 4.121 3.5 C 4.368 3.13 4.5 2.695 4.5 2.25 C 4.5 1.653 4.263 1.081 3.841 0.659 C 3.419 0.237 2.847 0 2.25 0 Z" fill="rgb(26, 32, 117)" height="4.4999981102994px" id="yz2qIzO5V" transform="translate(15.75 0)" width="4.499998110299384px"/><path d="M 2.25 0 C 1.805 0 1.37 0.132 1 0.379 C 0.63 0.626 0.342 0.978 0.171 1.389 C 0.001 1.8 -0.044 2.253 0.043 2.689 C 0.13 3.125 0.344 3.526 0.659 3.841 C 0.974 4.156 1.375 4.37 1.811 4.457 C 2.247 4.544 2.7 4.499 3.111 4.329 C 3.522 4.158 3.874 3.87 4.121 3.5 C 4.368 3.13 4.5 2.695 4.5 2.25 C 4.5 1.653 4.263 1.081 3.841 0.659 C 3.419 0.237 2.847 0 2.25 0 Z" fill="rgb(26, 32, 117)" height="4.500013446863562px" id="J33nzg30y" transform="translate(15.75 31.5)" width="4.499998110299384px"/><path d="M 3.871 0.667 C 3.554 0.35 3.151 0.133 2.711 0.044 C 2.271 -0.044 1.815 0 1.401 0.171 C 0.986 0.342 0.632 0.633 0.382 1.005 C 0.133 1.378 0 1.817 0 2.265 C 0 2.713 0.133 3.152 0.382 3.525 C 0.632 3.897 0.986 4.188 1.401 4.359 C 1.815 4.53 2.271 4.574 2.711 4.486 C 3.151 4.397 3.554 4.18 3.871 3.862 C 4.289 3.436 4.524 2.863 4.524 2.265 C 4.524 1.667 4.289 1.094 3.871 0.667 Z" fill="rgb(26, 32, 117)" height="4.5299983854213535px" id="o3Jdq1LcG" transform="translate(26.859 4.598)" width="4.523940000000028px"/><path d="M 3.871 0.668 C 3.554 0.35 3.151 0.133 2.711 0.044 C 2.271 -0.044 1.815 0 1.401 0.171 C 0.986 0.342 0.632 0.633 0.383 1.005 C 0.133 1.378 0 1.817 0 2.265 C 0 2.714 0.133 3.152 0.383 3.525 C 0.632 3.897 0.986 4.188 1.401 4.359 C 1.815 4.53 2.271 4.574 2.711 4.486 C 3.151 4.397 3.554 4.18 3.871 3.863 C 4.289 3.436 4.524 2.863 4.524 2.265 C 4.524 1.667 4.289 1.094 3.871 0.668 Z" fill="rgb(26, 32, 117)" height="4.530084132375148px" id="XDC7YK0d4" transform="translate(4.598 26.872)" width="4.523904000000017px"/><path d="M 4.5 2.25 C 4.5 1.805 4.368 1.37 4.121 1 C 3.874 0.63 3.522 0.342 3.111 0.171 C 2.7 0.001 2.247 -0.044 1.811 0.043 C 1.375 0.13 0.974 0.344 0.659 0.659 C 0.344 0.974 0.13 1.375 0.043 1.811 C -0.044 2.247 0.001 2.7 0.171 3.111 C 0.342 3.522 0.63 3.874 1 4.121 C 1.37 4.368 1.805 4.5 2.25 4.5 C 2.847 4.5 3.419 4.263 3.841 3.841 C 4.263 3.419 4.5 2.847 4.5 2.25 Z" fill="rgb(26, 32, 117)" height="4.499998110299398px" id="asAn08OfD" transform="translate(31.5 15.75)" width="4.5000134468635675px"/><path d="M 4.5 2.25 C 4.5 1.805 4.368 1.37 4.121 1 C 3.874 0.63 3.522 0.342 3.111 0.171 C 2.7 0.001 2.247 -0.044 1.811 0.043 C 1.375 0.13 0.974 0.344 0.659 0.659 C 0.344 0.974 0.13 1.375 0.043 1.811 C -0.044 2.247 0.001 2.7 0.171 3.111 C 0.342 3.522 0.63 3.874 1 4.121 C 1.37 4.368 1.805 4.5 2.25 4.5 C 2.847 4.5 3.419 4.263 3.841 3.841 C 4.263 3.419 4.5 2.847 4.5 2.25 Z" fill="rgb(26, 32, 117)" height="4.499998110299398px" id="MCcs4r2LC" transform="translate(0 15.75)" width="4.5px"/><path d="M 3.862 3.871 C 4.18 3.554 4.397 3.151 4.486 2.711 C 4.574 2.271 4.53 1.815 4.359 1.401 C 4.188 0.986 3.897 0.632 3.525 0.383 C 3.152 0.133 2.714 0 2.265 0 C 1.817 0 1.378 0.133 1.005 0.383 C 0.633 0.632 0.342 0.986 0.171 1.401 C 0 1.815 -0.044 2.271 0.044 2.711 C 0.133 3.151 0.35 3.554 0.667 3.871 C 1.094 4.289 1.668 4.524 2.265 4.524 C 2.863 4.524 3.436 4.289 3.862 3.871 Z" fill="rgb(26, 32, 117)" height="4.52394px" id="Fy2le1HRj" transform="translate(26.873 26.864)" width="4.529997332022967px"/><path d="M 3.863 3.871 C 4.18 3.554 4.397 3.151 4.486 2.711 C 4.574 2.271 4.53 1.815 4.359 1.401 C 4.188 0.986 3.897 0.632 3.525 0.383 C 3.152 0.133 2.713 0 2.265 0 C 1.817 0 1.378 0.133 1.005 0.383 C 0.633 0.632 0.342 0.986 0.171 1.401 C 0 1.815 -0.044 2.271 0.044 2.711 C 0.133 3.151 0.35 3.554 0.668 3.871 C 1.094 4.289 1.667 4.524 2.265 4.524 C 2.863 4.524 3.436 4.289 3.863 3.871 Z" fill="rgb(26, 32, 117)" height="4.523904000000001px" id="oUwiWstd4" transform="translate(4.598 4.589)" width="4.530001661593019px"/></g></svg>)
" height="36px" id="scAYi6Xom" transform="translate(2.995 2)" width="29.9999532385908px"/></svg>)

Written by
Published on
TLDR: This is part 1 of a series on low-precision GEMM kernels on MI355X. We use MakoraGenerate to write fast FP8 GEMMs in HIP. We go over what makes FP8 easy and hard, and release code along with performance results. The resulting kernels beat the publicly available AITER library provided by AMD on a variety of shapes. We'll be exploring FP4 and FP6 next, along with some clever features of the hardware we can exploit.
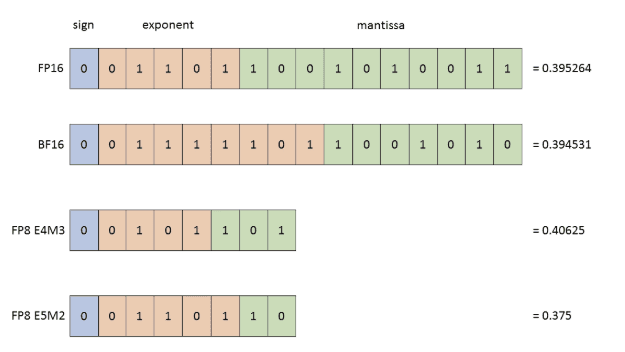
FP8 refresher
FP8 is an 8-bit floating point family of formats used to increase throughput and reduce memory bandwidth pressure compared to FP16 and BF16. The exact dynamic range and precision depend on the specific FP8 encoding. Two FP8 encodings are common in practice:
E4M3 (more mantissa precision, smaller range)
E5M2 (larger range, less precision)
FP8 GEMM is typically paired with explicit scaling. Instead of treating FP8 as a drop in replacement for FP16, you treat it as a compressed representation and recover a usable numeric range via scale factors.
Reference: NVIDIA
Achieving high performance
Most high performance FP8 GEMMs use one of these scaling schemes:
Per tensor scaling
Per row and per column scaling
Block scaling (scales per M block and N block, and sometimes per K block)
Block scaling represents a strategic compromise between accuracy and overhead, offering higher precision than global scaling with lower computational costs than per-element scaling. The MakoraGenerate must reason about these scaling factors because they directly influence both numerical correctness and kernel performance. Specifically, scaling decisions dictate how values are loaded, cached, and applied within the epilogue, or whether they are fused directly into the main compute loop.
Beyond raw compute, performance is governed by the interplay of data movement, memory layouts, tiling schedules, and precision strategies. Since an optimal kernel requires simultaneous shape and hardware awareness, a generate-and-evaluate loop is necessary to navigate these complex architectural trade-offs.
The MI355X (CDNA 4) targets very high peak throughput. In AMD’s published architecture material, peak FP8 throughput is shown at roughly 5 PFLOPs, around 1.9x faster than MI300X (CDNA 3).
AMD CDNA 4 architecture whitepaper:
Benchmark setup and results
Hardware: AMD MI355X
ROCm: 7.0
Kernel type: FP8 GEMM
Baseline: reference implementation from AITER
This section summarizes benchmark results and highlights the cases where the agent generated kernels match or exceed the baseline.
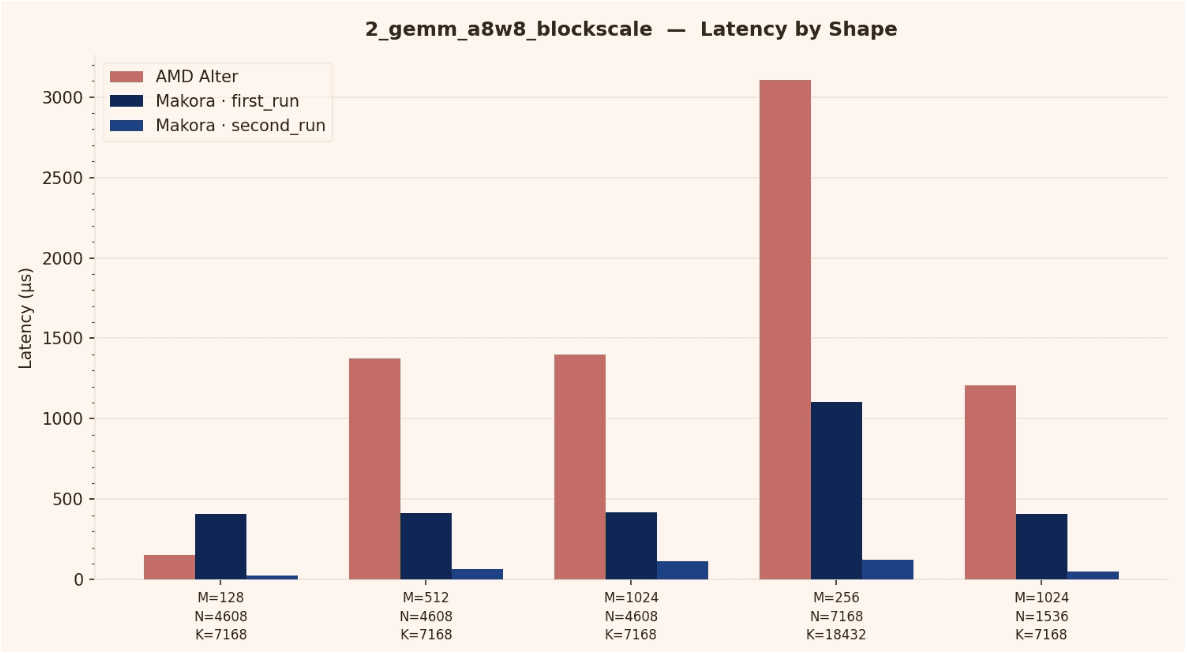
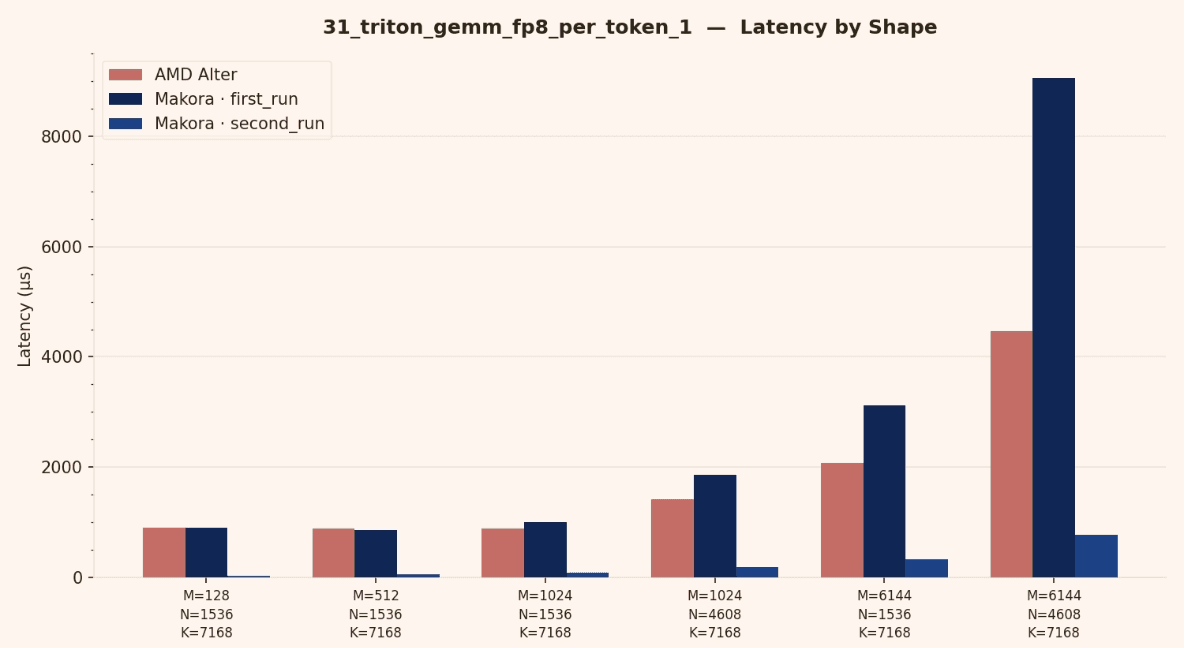
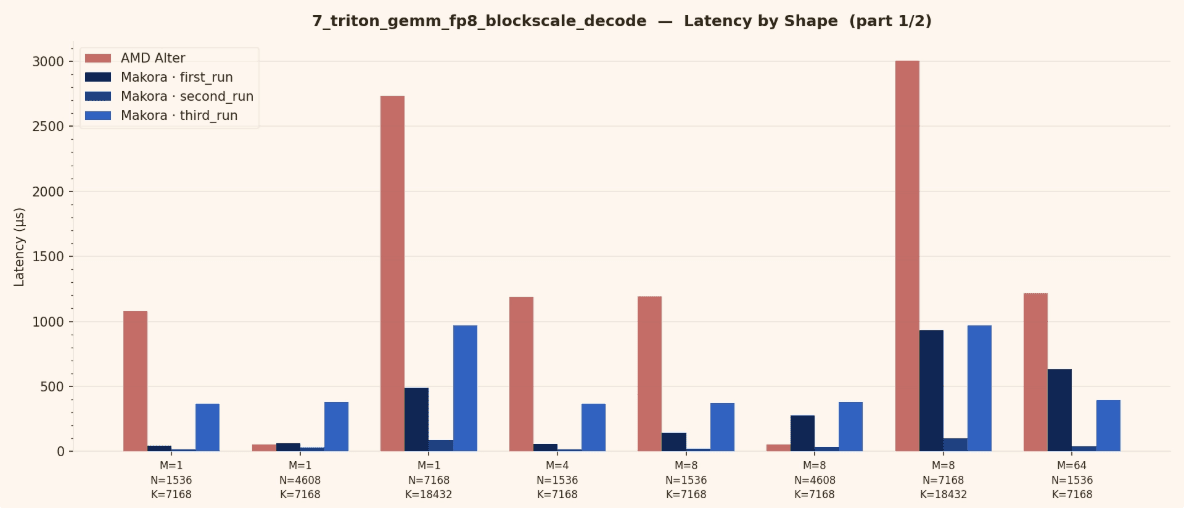
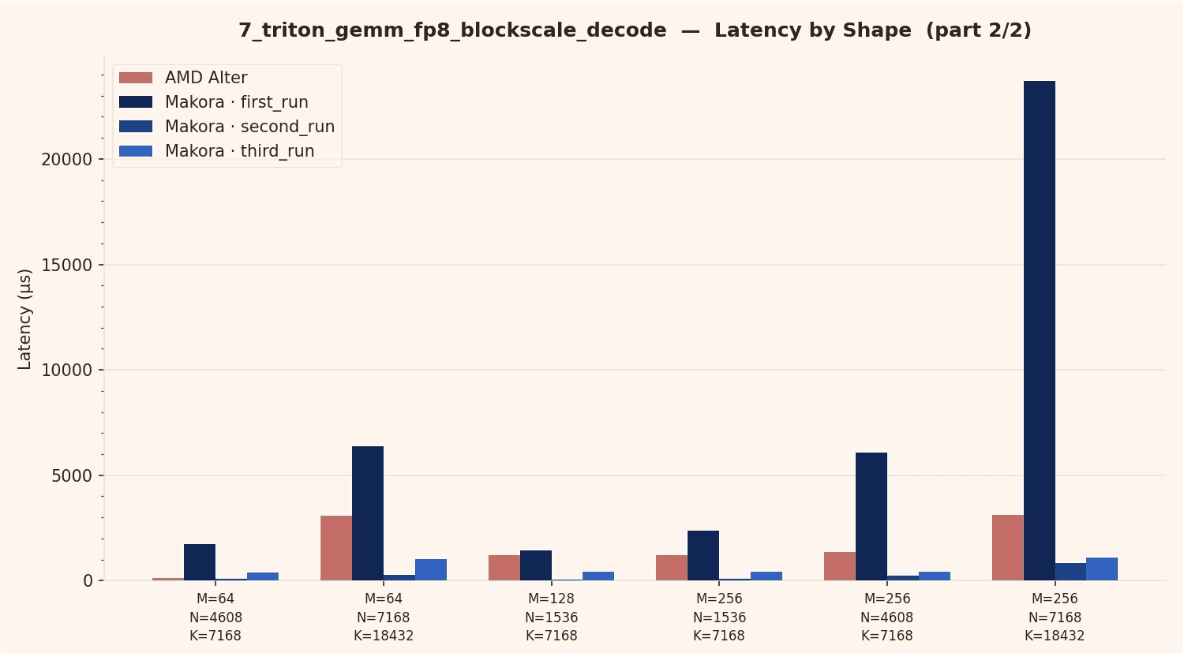
Notes on what improved
Across iterations, generation time decreased significantly while performance increased. The agent learns from previous experiments, reuses what works, and keeps refining the kernel.
Average generation time per iteration:
First run: about 6 hours
Second run: about 2 hours
Third run: about 30 minutes to a state of the art kernel
The key takeaway is that the optimization loop is getting faster and more effective over time, as the agent accumulates prior knowledge and converges with fewer iterations.
Code highlights
The snippets below are examples of the kinds of transformations the agent produces when optimizing FP8 GEMM. I will keep adding excerpts here.
This excerpt shows an MFMA inner loop with four independent MFMA calls to increase instruction level parallelism. After the MFMA loop, the code applies A and B scale factors before accumulating into FP32.
Key ideas to notice:
Multiple independent MFMA calls to keep the pipeline busy
Packing FP8 into 8 byte chunks
Scale application fused close to accumulation
Split K, fused heuristics, and dtype details
This excerpt documents a subtle FP8 detail and the correction applied in the kernel.
And the corresponding accumulation into a temporary FP32 buffer for split K:
Latest
From the blog
The latest industry news, interviews, technologies, and resources.




